Mouthwash: Viewpoints
August 31, 2011 - Games / Mouthwash

In previous discussions of Mouthwash, I’ve mentioned that there are four domains in which actions can take place: goals, emotions, viewpoints, and relationships. I’ve talked a bit about goals and emotions, which brings me to viewpoints. This was the domain that scared me the most when I started sketching out Mouthwash, because it’s the domain that deals with knowledge.
Getting computers to represent knowledge is like getting humans to use logic. You’d think they’d be good at it, but they’re not, and in fact they’re bad at it because they’re so well adapted for other functions. Computers have pretty much unlimited perfect memory for data. As a result, they don’t need to aggregate or generalize those data to store them. Humans do, which is why we have knowledge. Knowledge as we humans conceive of it is not anything like data. It’s a messy, overlapping, interconnected organic meat-based something. Our attempts to reproduce it digitally have so far been awkward and/or laughable. We just end up producing data with some meta-data on top. It never has the same useful (or problematic) properties as meat-based knowledge.*
That said, I can’t imagine coming up with fun conversational gameplay that doesn’t deal with knowledge on some level. You need a knowledge representation to argue, to lie, to tell stories, to question a suspect, to solve a mystery, etc. Moreover, a debate with winners and losers is the point of most direct analogy between a conversation system and traditional battle systems. If I get that right, it might be one of the easiest things to make fun in a familiar way. Debate gameplay requires that each competing agent be able to compare ideas, offer evidence in favor or against their idea, and pick apart their opponent’s idea piece by piece. You could just put their persuasiveness stats up against each other and roll for it, but that leaves no room for tactics.
So I need a knowledge representation, but I don’t want to get mired down in a bunch of philosophical debates or obscenely complex representations. At one point, I very nearly committed myself to building a giant graph of every relevant thing and concept in the game world, to which each agent would have varying access. Oops, but what if people have false beliefs, or different opinions on a subject? Looks like everybody needs their own copy of the world graph! Needless to say, this does not scale.
The snarl I kept running into was this: the kind of gameplay I wanted seemed to need semantics, and semantics are exactly what data representations can’t handle without exploding in complexity. To take the Community example pictured above, say two agents, Annie and Jeremy, are debating a topic: Is man good or evil? Annie offers an argument in favor of the “man is evil” side: survival of the fittest wires us to be selfish. Jeremy wants to rebut her argument. He has a bunch of facts and quotes at his disposal, but how does he pick which one is relevant? He has to know which of his facts contradict Annie’s statement, which implies that he knows what Annie’s statement means and what all his facts mean. And meaning is the last thing I want to represent.
After being stuck on that problem for a while, it finally occurred to me that the important information isn’t the meaning: it’s the contradiction. I don’t need to know anything about the semantics if I just know which statements contradict each other and which agree. That’s obviously useful information for debate gameplay, but it also applies in other situations. A detective trying to solve a case will need to compare the statements of various witnesses for discrepancies. Lying to someone may involve resolving contradictions between your story and their beliefs. A whole world of psychological conflict can arise from the difference between how I see you and how you see yourself.
This insight produced the viewpoint data structure. So far, it’s pretty simple. Each agent has a set of viewpoints in its mental inventory. Each viewpoint has a topic and a related list of statements that the agent believes. The statements are just text strings. Only their order in the list contains any information about their meaning. The shape of each viewpoint is the same across agents, and statements that occupy the same position are always about the same thing. If those statements don’t match, the agents disagree on that point. So Annie and Jeremy’s viewpoints might look something like this:

Now, all Jeremy needs to know is the number of the statement his opponent said, and he can produce his own contradicting belief. No semantics, no graphs. Just lists of sentences.
There are a couple of nice things that come out of this data structure. If an agent doesn’t know something about a particular topic, the viewpoint directly represents gaps in her knowledge. Agreement scores can be calculated quickly. It’s lightweight enough that each agent can have a ton of these without things getting too memory-intensive or slow to search. You can deal with an argument in a couple different ways: by picking apart an opponent’s viewpoint piece-by-piece, or by completely replacing his viewpoint with yours.
There might be other embellishments I want to add to this basic structure. For example, ratings of how confident the agent is in each statement might be useful. So would information about the source of each statement, which would support detective gameplay, gossip, and debate. (“My quote is just from a simple desert handyman… named Jesus.”) Still, at this point I’m confident that this is a good starting point for a useful knowledge representation that dodges most of the pitfalls.
* Unless it includes significant human input at some point in the process, as in every useful machine learning application I can think of.
Related Posts
 Trapped in Amber Last time I checked in with you guys about Mouthwash, I mentioned that I was no longer sure I wanted to use D&D-style dice rolls to determine skill effects, but didn't know what to […]
Trapped in Amber Last time I checked in with you guys about Mouthwash, I mentioned that I was no longer sure I wanted to use D&D-style dice rolls to determine skill effects, but didn't know what to […]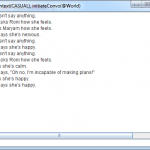 The Next Step
Fuckin' Shakespeare, I know. But this insipid nonsense represents an important step forward for Mouthwash, because Maryam (an NPC) is now capable of having goals: in this case, making […]
The Next Step
Fuckin' Shakespeare, I know. But this insipid nonsense represents an important step forward for Mouthwash, because Maryam (an NPC) is now capable of having goals: in this case, making […] Chemical Reactions
This is up a bit late. I blame Labor Day! Also, getting swamped at work. Anyway, last week I was mainly playing through last May's Experimental Gameplay Project entries, with the theme […]
Chemical Reactions
This is up a bit late. I blame Labor Day! Also, getting swamped at work. Anyway, last week I was mainly playing through last May's Experimental Gameplay Project entries, with the theme […]